Взвешенная сортировка или как работать с большим количеством конверсий
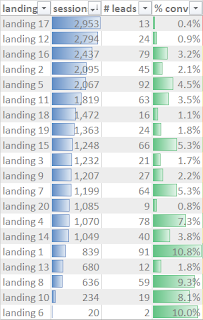
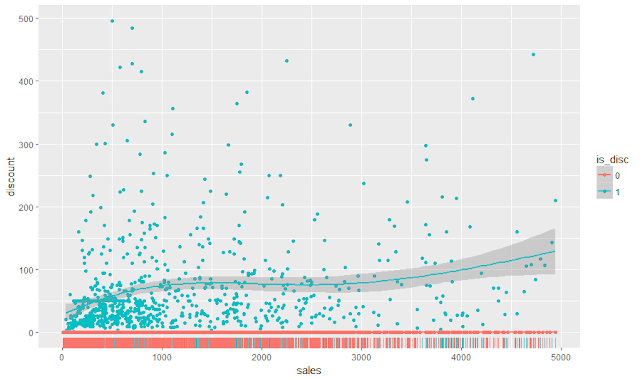
Сегодня я хочу поделиться с вами простым, но, на мой взгляд, достаточно эффективным подходом к анализу конверсий. Например, у вас есть 20 (а м.б. 2000+) лендингов на которые приходит трафик. На этих лендингах клиенты совершают целевые дейтсвия, в результате чего происходит конверсия. Вопрос, как понять какие лендингы самые важные для бизнеса? Сортировка по сессиям Если мы отсортируем лендинги по сессиям, то мы поймем откуда заходит больше всего трафика. Сделав это, мы видим, что самые посещаемые страницы, являются самыми низко-конверсионными. Причем, когда трафик начинает уменьшаться, то конверсия растет. Обычно это связано с тем, что часто такие страницы очень широкие по семантике. Поэтому трафика там много, но целевых заходов - мало. Так, например, трафика на ` landing 17 ` в 12 раз больше, чем на ` landing 10 `. Но, в тоже время, лидов с ` landing 10 ` мы получаем в 2 раза больше, чем из ` landing 17 `. Поэтому потеря небольшого объема трафика с ` landing 10...