Продуктовая аналитика: влияние продуктовых фич на ретеншн

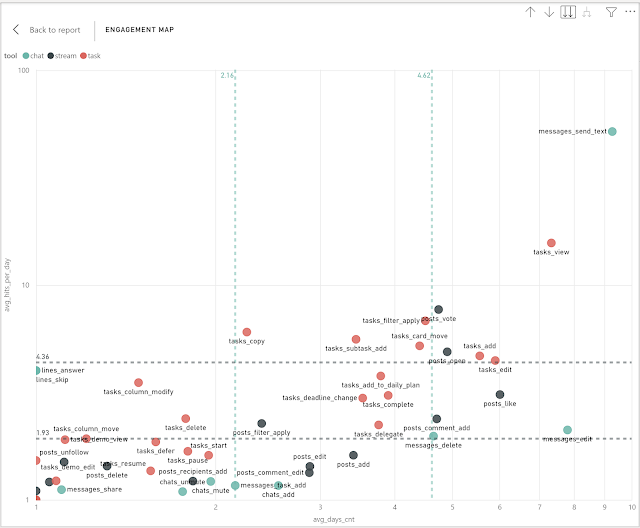
Предыдущих три поста были в сущности о том, как можно было бы разделить наши продуктовые фичи на несколько групп: core , power и casual . И делали мы это разными способами: (1) сравнивали популярность фичей с их ежедневной повторяемостью (2) сравнивали дневную интенсивность фичей с их ежедневной повторяемостью (3) применили кластеризацию к интенсивности. Давайте остановимся на минутку и спросим себя - а зачем нам вообще разделять продуктовые фичи? На самом деле, мы не случайно делили их по популярности и особенно по интенсивности. Мы хотели понять, какие фичи создают привычку повторного использования. С одной стороны, если мы посмотрим на популярность фичи (например, % MAU) мы легко можем разбить этот показатель на "новых" и "вернувшихся". Если доля вернувшихся будет условно большая и не будет падать со временем, значит можно сделать вывод, что клиенты регулярно возвращаются за этой фичей. С другой стороны, дневная интенсивность и особенно ежедневная повторяемос...