Кластерный анализ клиентов. Номинал покупки.
Ранее, я в значительной степени полагался на Excel. На мой взгляд, это самый доступный и в тоже время недорогой из аналитических инструментов для маркетолога. Ведь, с одной стороны, Excel есть у многих пользователей. Обмениваться Excel-файлами очень легко. С другой стороны, к отчетам в Excel в значительной степени привыкли топ-менеджеры многих компаний.
Однако, со временем, я начал сталкиваться с ситуациями, где надо не просто что-то рассчитать, а понять почему цифра и/или тренд такие, какие есть, найти факторы, которые определили результат. Я активно пользуюсь сводными таблицами т.к. они позволяют быстро делать разные срезы (drill-down) и это дает свои плоды. Часто - но далеко не всегда.
В последнее время я больше думаю о базовой математике и алгоритмах, которые стоят за продвинутой аналитикой. Откладывать изучение и использование алгоритмов машинного обучения дальше уже нельзя. Это вопрос выживания для современного аналитика.
Для себя я планирую ~ раз в 4 недели описывать свой опыт применения алгоритмов машинного обучения к проблемам, которые меня, как маркетолога, волнуют. Очевидно, что это не всегда будут сильные и отточенные решения. Однако я и не жизни спасаю. Это маркетинг - мы просто стараемся заработать сегодня немного больше, чем вчера. Так что, поехали!
Сегодня я буду говорить о кластеризации, как об одном из алгоритмов машинного обучения, который позволяет открыть для себя скрытые патерны внутри свои данных.
Итак, есть задача - понять как делают покупки ваши клиенты?
Здесь на ум приходит сразу приходит 2 среза:
Обратите внимание на метрику ARPU. Она указывает какой средний доход приносит клиент в каждом из сегментов. Так например клиент из сегмента с ATV(100) в среднем приносит $101.4.
Однако как клиент генерирует такую сумму?
Однако, со временем, я начал сталкиваться с ситуациями, где надо не просто что-то рассчитать, а понять почему цифра и/или тренд такие, какие есть, найти факторы, которые определили результат. Я активно пользуюсь сводными таблицами т.к. они позволяют быстро делать разные срезы (drill-down) и это дает свои плоды. Часто - но далеко не всегда.
В последнее время я больше думаю о базовой математике и алгоритмах, которые стоят за продвинутой аналитикой. Откладывать изучение и использование алгоритмов машинного обучения дальше уже нельзя. Это вопрос выживания для современного аналитика.
Для себя я планирую ~ раз в 4 недели описывать свой опыт применения алгоритмов машинного обучения к проблемам, которые меня, как маркетолога, волнуют. Очевидно, что это не всегда будут сильные и отточенные решения. Однако я и не жизни спасаю. Это маркетинг - мы просто стараемся заработать сегодня немного больше, чем вчера. Так что, поехали!
Сегодня я буду говорить о кластеризации, как об одном из алгоритмов машинного обучения, который позволяет открыть для себя скрытые патерны внутри свои данных.
Итак, есть задача - понять как делают покупки ваши клиенты?
Здесь на ум приходит сразу приходит 2 среза:
- по среднему чеку и
- по количеству покупок.
 |
| Сводная Таблица со статистикой по номиналам. |
Обратите внимание на метрику ARPU. Она указывает какой средний доход приносит клиент в каждом из сегментов. Так например клиент из сегмента с ATV(100) в среднем приносит $101.4.
Однако как клиент генерирует такую сумму?
- один раз купил за $100 и один раз за $1?
- два раза купил за $50 и один раз за $1?
- пять раз купил за $20 и один раз купил за $1?
- и т.д.
Комбинаций для генерации каждого ARPU могут быть десятки. И хотя у нас на руках есть кросс-метрика # trans/buyer которая, теоретически, может отсекать ряд комбинаций, она тем не менее, не решает задачу определения часто повторяемых комбинаций внутри сегмента.
Вот здесь нам на помощь и приходит алгоритм кластерный анализ.
Кластерный анализ (кластеризация) это метод машинного обучения который самостоятельно (без нашего опыта) найдет естественные группы клиентов со схожим патерном покупок по номиналам и разложит их по кластерам.
Существует 2 часто используемых подхода к кластеризации:
В партиционном подходе вы заранее фиксируете количество необходимых вам кластеров. Затем кейсы случайным образом распределяются на K групп и затем перемещаются из кластера в кластер пока не будут сформированы устойчивые кластера.
Итак, предварительно оптимальное K = 4. Однако, часто полученные кластера нестабильны, поэтому идем дальше.
Как мы видим один из кластеров достаточно нестабилен. Поэтому давайте также оценим насколько стабильны конфигурации с 3-мя и 5-ю кластерами.
Кластерный анализ (кластеризация) это метод машинного обучения который самостоятельно (без нашего опыта) найдет естественные группы клиентов со схожим патерном покупок по номиналам и разложит их по кластерам.
Существует 2 часто используемых подхода к кластеризации:
- иерархический
- партиционный
В партиционном подходе вы заранее фиксируете количество необходимых вам кластеров. Затем кейсы случайным образом распределяются на K групп и затем перемещаются из кластера в кластер пока не будут сформированы устойчивые кластера.
Более того, в рамках каждого подхода есть десятки конкретных алгоритмов к многим из которых еще и применимы разные метрики расчета расстояния.
Мы будем использовать партиционный подход, алгоритм kmeans с Евклидовым расстоянием.
При расчете кластеров есть ряд нюансов, которые нужно учесть:
- Выбрать подходящие атрибуты для кластеризации. У нас атрибут один - это номинал покупки. К слову сказать кластеризации становится намного полезнее если у вас таких атрибутов много.
- Нормализовать данные. Разные атрибуты имеют разную размерность. Например номинал измеряется от 1 до 100. Допустим у вас еще один атрибут - количество покупок и оно измеряется от 0 до 12. В этом случае атрибут номинал из-за более высокой размерности будет влиять на кластеризацию намного больше, скрывая важность других атрибутов.
- Убедиться, что в данных нет выбросов.
- Выбрать метрику для расчета расстояния. Отметьте, что Евклидово расстояние подходит только для числовых атрибутов.
- Определить количество необходимых кластеров.
- Убедиться в стабильности кластеров.
- Убедиться, что полученные кластера можно проинтерпретировать.
Давайте определим количество кластеров.
Существует два базовых подхода:
- построить wss-чарт (R-пакет flexclust)
- рассчитать авто-индексы (R-пакет NbClust)
Мы будем использовать wss-чарт. Суть метода в том, что как только график начинает уменьшаться не так резко, это вероятная точка с оптимальным количеством кластеров. Я провел через эту точку красную линию.
 |
| WSS-чарт для оценки оптимального K. |
Итак, предварительно оптимальное K = 4. Однако, часто полученные кластера нестабильны, поэтому идем дальше.
Давайте построим на базе рассчитанных кластеров новые синтетические кластера и посмотрим насколько они стабильны по отношению к расчетным (R-пакет fpc).
Мы будем использовать индекс похожести Jaccard. Суть метода в том, что через сэмплирование по исходным данным строятся новые наборы синтетических кластеров, рассчитывается Jaccard-индекс и затем рассчитывается среднее среди таких индексов по каждому кластеру. Если этот усредненный индекс < 0.85 то весьма вероятно, что оригинальный найденный кластер ненастоящий (т.к. он неустойчивый).
Ниже расчет Jaccard-индекс для 4-х кластеров.
 |
| Jaccard-индекс для оценки стабильности 4-х кластеров. |
Как мы видим один из кластеров достаточно нестабилен. Поэтому давайте также оценим насколько стабильны конфигурации с 3-мя и 5-ю кластерами.
 |
| Jaccard-индекс для оценки стабильности 3-х кластеров. |
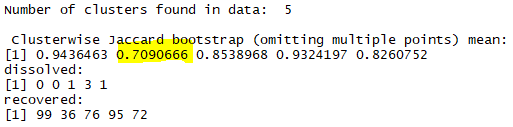 |
| Jaccard-индекс для оценки стабильности 5-ти кластеров. |
Итак, наиболее стабильная конфигурация с 3-мя кластерами.
Давайте ее визуализируем и попробуем проинтерпретировать.
 |
| Распределение номиналов по 3-м кластерам. |
Что мы видим?
Кластер #1. Самый многочисленный (70%). В нем клиенты, которые, в основном, делают покупки с номиналом $1. Покупки с номиналами $5 и $10 - минорны.
Кластер #2. Второй по численности кластер (18%). В нем клиенты активно делают покупки с номиналом $5 и чуть менее активно с номиналом $1. Покупки с номиналом $10 - минорны.
Кластер #3. Самый маленький по численности кластер (12%). В нем клиенты активно делают покупки с номиналом $10 и чуть менее активно с номиналом $1. Обратите также внимание, что покупки с номиналом $20 значимы только для этого кластера.
РЕЗЮМЕ
Используя кластеризацию по номиналу покупки мы смогли выявить 3 кластера клиентов.
Кластер #1 это определенно чувствительные к цене клиенты. Офера > $1 для них с большой степенью вероятностью - нерелевантны.
Кластер #3 это высокодоходные клиенты. Тем не менее, они регулярно пользуются самым дешевым номиналом в $1 и эта хорошая возможность реактивировать их таким офером при достижении порога неактивности. Также не стоит предлагать им офер в $5 т.к. это создает упущенную выгоду.
Также мы видим, что дорогие номиналы в $50 и $100 малочисленны. Хотя они и вошли в разные кластера в разном объеме их разница между кластерами незначительна, поэтому они выделены серым цветом.


Comments
Post a Comment