Продуктовая аналитика: влияние продуктовых фич на ретеншн
Предыдущих три поста были в сущности о том, как можно было бы разделить наши продуктовые фичи на несколько групп: core, power и casual. И делали мы это разными способами: (1) сравнивали популярность фичей с их ежедневной повторяемостью (2) сравнивали дневную интенсивность фичей с их ежедневной повторяемостью (3) применили кластеризацию к интенсивности.
Давайте остановимся на минутку и спросим себя - а зачем нам вообще разделять продуктовые фичи?
На самом деле, мы не случайно делили их по популярности и особенно по интенсивности. Мы хотели понять, какие фичи создают привычку повторного использования.
С одной стороны, если мы посмотрим на популярность фичи (например, % MAU) мы легко можем разбить этот показатель на "новых" и "вернувшихся". Если доля вернувшихся будет условно большая и не будет падать со временем, значит можно сделать вывод, что клиенты регулярно возвращаются за этой фичей.
С другой стороны, дневная интенсивность и особенно ежедневная повторяемость дают нам еще более понятную картинку того, как именно формируется привычка повторного использования фичи.
Но можем ли мы подойти к этому вопросу более формально?
Давайте попробуем вместе ответить на этот вопрос.
Первое, с чего мы начнем - это определим для себя цикл повторного использования продукта. Во многом, конечно, это зависит от специфики продукта. Из того, что я встречал ранее, это как правило, либо еженедельная либо ежемесячная цикличность.
Затем, нам нужно рассчитать флаг ретеншн (вернулся клиент или нет) для каждого клиента воспользовавшегося той или иной фичей в следующем цикле.
ВАЖНО: нужно брать статистику по клиентам возрастом старше 2-х месяцев, чтобы у каждого такого клиента было достаточно времени, чтобы вернуться в следующем цикле.
Ретеншн флаг можно рассчитать на нескольких уровнях:
- на уровне фичи
- на уровне инструмента, в который входит фича
- на уровне всего продукта
Обычно я смотрю ретеншн на уровне всего продукта.
Определив уровень ретеншн и рассчитав ретеншн флаг, дальше мы можем задать себе несколько важных вопросов:
- Какие фичи имеют наибольший вклад в ретеншн?
- Сколько дней нужно повторно использовать фичу, чтобы вероятность ретеншн клиента стала выше среднего?
 |
| Product features ranked by impact to retention. (кликните, чтобы увеличить картинку) |
- если WOE < 0, то шансы возврата клиента в этом бине ниже среднего.
- если WOE = 0, то шансы возврата клиента такие же как и невозврата.
- если WOE > 0, то шансы возврата клиента в этом бине выше среднего.
 |
| Weight Of Evidence (WOE) for product feature `tasks_add`. (кликните, чтобы увеличить картинку) |
 |
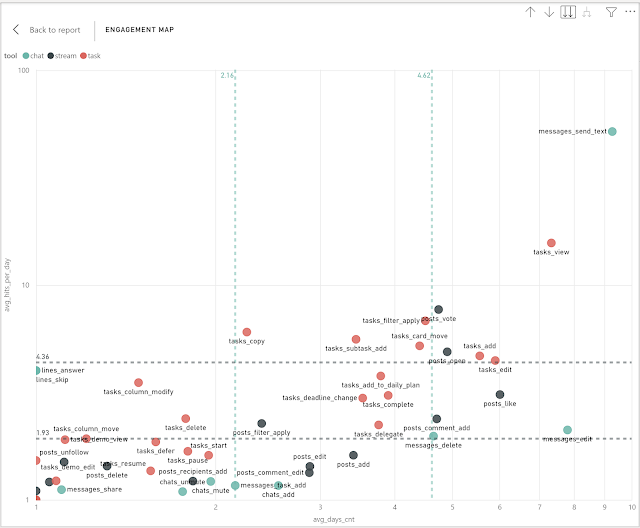
| Core features selection using different approaches. (кликните, чтобы увеличить картинку) |
- использование статистического подхода - 80% персентиль, который выделяет самое важное
- использование 2-го измерения, которое страхует нас от выбросов по первому измерению
- количество использований фичи в день (дневная интенсивность) или
- количество дней использования фичи (ежедневная повторяемость)?
 |
| `avg_days_cnt` vs `avg_hits_per_day` vs `IV`. (кликните, чтобы увеличить картинку) |
- day_cnt - количество дней использования
- hit_cnt - общее количество использований за месяц
- user_cnt - количество пользователей, использующих фичу
- hits_per_day - общее количество использований за один день
- event - название того или иного события
 |
| Signals strength comparisons. (кликните, чтобы увеличить картинку) |
- цикл повторного использования продукта (еженедельный, ежемесячный или даже ежедневный)
- вертикаль (например, для игр скорее всего решающим будет сигнал hits_per_day)
- инструмент (подсистема) внутри продукта
- day_cnt почти всегда топовый сигнал связанный с ретеншн
- hits_per_day почти всегда самый слабый сигнал связанный с ретеншн
- в зависимости от инструмента общее количество совершенных действий (hit_cnt) и/или конкретное событие (event) иногда могут быть более важными с точки зрения количества информации о ретеншн
- расчеты по двум осям с использованием схемы персентилей 50/80 неплохо аппроксимируют ретеншн.
- балансировка расчета качества - объемом, и наоборот позволяет делать надежные выводы
- IV - доступный статистический подход к оценке влияния фич на ретеншн.

Nice
ReplyDelete