LTV при привлечении - нюансы есть всегда!
Сегодня я продолжу тему LTV. В прошлом посте я показывал возможную финансовую отдачу от клиентов, если они привлечены с учетом LTV, а не, как обычно, на основе CAC.
Очевидно, что модель, которую я показывал в прошлый раз, упрощенная и к ней имеется ряд вопросов. Давайте вместе пройдемся по таким возможным вопросам.
(1) LTV - прогнозная величина. Насколько эта метрика точная?
Это зависит от ваших возможностей по сбору данных и особенно от последующей аналитики. Если у вас нет полноценного доступа к данным из БД, а также возможности контролировать какие данные туда писать, то вопрос расчета LTV для вас будет малоподъемным.
Основные подходы для расчета LTV следующие:
(2) Какое значение LTV считается средним для моего e-commerce?
Я категорически не рекомендую вам даже думать про среднее значение LTV для вашего бизнеса. Это может привести вас к ложным выводам.
Давайте обратимся к прошлому примеру.
Среднее LTV для всех платных каналов = 431 грн.
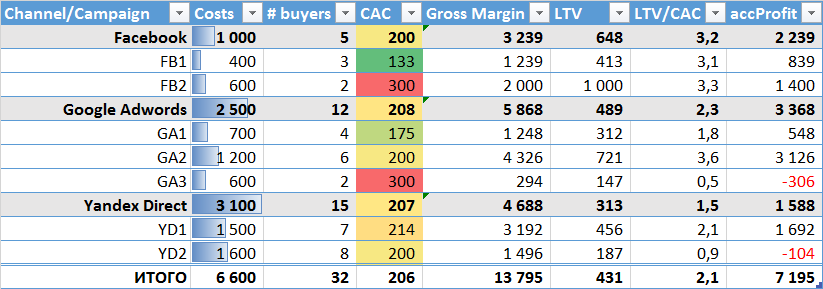
Если использовать это среднее значение LTV для всех каналов и РК (т.е. считать, что все клиенты равноценны), то картина расчета прибыльности для каналов и РК меняется кардинально:

Во-первых: все РК стали прибыльными (см. колонку accProfit). Мы же знаем, что это не так.
Во-вторых: многие РК в которых LTV был выше среднего существенно потеряли в прибыли (см. колонку %lift). Т.о. мы несправедливо занизили значимость этих РК.
В-третьих: канал Yandex.Direct, который до оптимизаций был самым неприбыльным каналом, после применения среднего LTV стал наоборот - самым прибыльным.
Поэтому, старайтесь рассчитать LTV не вообще, а для конкретного канала привлечения (а лучше для конкретной РК внутри канала).
Если этого не делать, а исходить из того, что все клиенты в каналах равноценны, то результат будет плачевный.
Учитывая использование данных из семьи когорт, этот вопрос мало актуален.
Почему?
Я опираюсь на результат семьи когорт (6+). Это значит, что я использую результаты не одного замера, а целых Х замеров.
Конечно, в каждой из когорт (в каждом замере) данные несколько отклоняются друг от друга. Но, тем не менее, каждый раз результат у LTV-based когорт выше, чем у других вариантов. И естественно совокупный результат намного лучше.
Очевидно, что модель, которую я показывал в прошлый раз, упрощенная и к ней имеется ряд вопросов. Давайте вместе пройдемся по таким возможным вопросам.
(1) LTV - прогнозная величина. Насколько эта метрика точная?
Это зависит от ваших возможностей по сбору данных и особенно от последующей аналитики. Если у вас нет полноценного доступа к данным из БД, а также возможности контролировать какие данные туда писать, то вопрос расчета LTV для вас будет малоподъемным.
Основные подходы для расчета LTV следующие:
- подход на основе ARPU (большая погрешность)
- подход на основе Cohorts (приемлемая погрешность)
- подход на основе моделей вероятностей (минимальная погрешность)
- подход LTD (Lifetime to Date). При этом подходе LTV не прогнозируется, а рассчитывается ценность клиента на определенную дату.
- подход LCG (LifeCycle Grid). При этом подходе LTV вообще не рассчитывается - оптимизируется так называемый relative value.
(2) Какое значение LTV считается средним для моего e-commerce?
Я категорически не рекомендую вам даже думать про среднее значение LTV для вашего бизнеса. Это может привести вас к ложным выводам.
Давайте обратимся к прошлому примеру.
Среднее LTV для всех платных каналов = 431 грн.
Если использовать это среднее значение LTV для всех каналов и РК (т.е. считать, что все клиенты равноценны), то картина расчета прибыльности для каналов и РК меняется кардинально:
Во-вторых: многие РК в которых LTV был выше среднего существенно потеряли в прибыли (см. колонку %lift). Т.о. мы несправедливо занизили значимость этих РК.
В-третьих: канал Yandex.Direct, который до оптимизаций был самым неприбыльным каналом, после применения среднего LTV стал наоборот - самым прибыльным.
Поэтому, старайтесь рассчитать LTV не вообще, а для конкретного канала привлечения (а лучше для конкретной РК внутри канала).
Если этого не делать, а исходить из того, что все клиенты в каналах равноценны, то результат будет плачевный.
- Вы не сможете понять откуда приходят стоящие клиенты, а откуда - нет.
- Вы не будете знать насколько стоящие (с точки зрения денег) клиенты, которых вы привели.
- Более того, вы не сможете понять окупаются ли ваши клиенты (LTV / CAC).
(3) В прошлом посте было допущение, что при перераспределении бюджета в сторону компаний с высоким LTV конверсия в РК останется на том же уровне. Насколько это реально?
Строго говоря, определенные отклонения от расчета будут происходить всегда. Ваши отклонения возможны по двум осям: по оси затрат и по оси доходов.
Отклонения по оси затрат.
Работать с отклонениями по оси затрат проще. Даже после того как когорта была привлечена в месяце Х, в следующих месяцах у вас все еще есть возможности понизить САС.
Как?
Не забываем, что каждый новый активировавшийся клиент из когорты месяца Х понижает CAC в следующих месяцах (X + n), т.к. CAC считается, используя аккумулятивное количество клиентов в когорте.
Для вас это хорошая возможность максимально снизить (читай "выровнять") CAC до уровня, который был до оптимизации, а м.б. даже ниже этого уровня.
Отклонения по оси доходов.
Работать с отклонениями по оси дохода намного сложнее. Одно дело создать ситуацию при которой клиент сделает первую (тестовую) покупку. Другое дело сформировать клиента, который покупает регулярно.
Практика показывает, что идентичность когорты часто определяет последующее поведение. В этом и прелесть когорты, у них изменчивость, как правило, достаточно мала.
Более того, возможность работать на всем протяжении Жизненного Цикла Клиента остается по-прежнему в ваших руках.
А это значит, что нужно:
Строго говоря, определенные отклонения от расчета будут происходить всегда. Ваши отклонения возможны по двум осям: по оси затрат и по оси доходов.
Отклонения по оси затрат.
Работать с отклонениями по оси затрат проще. Даже после того как когорта была привлечена в месяце Х, в следующих месяцах у вас все еще есть возможности понизить САС.
Как?
Не забываем, что каждый новый активировавшийся клиент из когорты месяца Х понижает CAC в следующих месяцах (X + n), т.к. CAC считается, используя аккумулятивное количество клиентов в когорте.
Для вас это хорошая возможность максимально снизить (читай "выровнять") CAC до уровня, который был до оптимизации, а м.б. даже ниже этого уровня.
Отклонения по оси доходов.
Работать с отклонениями по оси дохода намного сложнее. Одно дело создать ситуацию при которой клиент сделает первую (тестовую) покупку. Другое дело сформировать клиента, который покупает регулярно.
Практика показывает, что идентичность когорты часто определяет последующее поведение. В этом и прелесть когорты, у них изменчивость, как правило, достаточно мала.
Более того, возможность работать на всем протяжении Жизненного Цикла Клиента остается по-прежнему в ваших руках.
А это значит, что нужно:
- делать не короткую (1-я покупка), а долгую активацию (довести новичка до 4 покупок)
- работать над вовлеченностью (UX, personalization)
- работать над удержанием (LCG)
(4) В прошлом посте выборка была очень маленькая. Принималась ли во внимание статистическая значимость результата?
Учитывая использование данных из семьи когорт, этот вопрос мало актуален.
Почему?
Я опираюсь на результат семьи когорт (6+). Это значит, что я использую результаты не одного замера, а целых Х замеров.
Конечно, в каждой из когорт (в каждом замере) данные несколько отклоняются друг от друга. Но, тем не менее, каждый раз результат у LTV-based когорт выше, чем у других вариантов. И естественно совокупный результат намного лучше.
(5) А как насчет A/A теста и/или A/B теста?
АА-тест нужен для того, чтобы проверить правильно ли инструмент сплитит трафик, т.е. попадают ли в каждую из групп одинаковое распределение пользователей из разных каналов.
При оптимизации по LTV сплита нет вообще. Выбираются РК, которые определены заранее. При этом LP и последующее обслуживание остается неизменным. Т.е. на самом деле тест делается на исторических данных за исследовательским столом, а не "в поле". Аналогичная логика рассуждения применима к AB-тесту.
Отдельно хочу отметить, что современные АА/AB-тесты работают по первому событию (первой покупки каждого участника теста). Они не предназначены для отслеживания цепочки событий на клиента (например 10-20 покупок).
Поэтому крупные e-commerce делают свое решение для тестов, которое может опираться на статистику целой цепочки покупок, т.к. именно в цепочке повторных покупок создается 95% LTV.
При оптимизации по LTV сплита нет вообще. Выбираются РК, которые определены заранее. При этом LP и последующее обслуживание остается неизменным. Т.е. на самом деле тест делается на исторических данных за исследовательским столом, а не "в поле". Аналогичная логика рассуждения применима к AB-тесту.
Отдельно хочу отметить, что современные АА/AB-тесты работают по первому событию (первой покупки каждого участника теста). Они не предназначены для отслеживания цепочки событий на клиента (например 10-20 покупок).
Поэтому крупные e-commerce делают свое решение для тестов, которое может опираться на статистику целой цепочки покупок, т.к. именно в цепочке повторных покупок создается 95% LTV.


Comments
Post a Comment