Transition Matrix: введение в систему роста вашего продукта

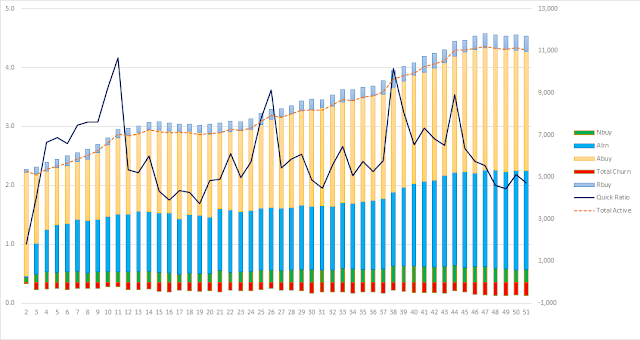
Итак, в прошлой статье мы разбирали как концептуально рассчитывается Quick Ratio . Quick Ratio полезный показатель роста продукта, но он не самодостаточный. Он позволяет определить текущий темп роста и фокусировать команды на поддержании нужного темпа роста продукта. Но, чтобы по-настоящему управлять ростом, нужно погрузиться в детали: нужно понять как правильно считать компоненты Quick Ratio, как начать мыслить развитием клиентов: кого нужно развивать, кого лучше не трогать, кого возвращать из других сегментов обратно, кого отпускать. Итак, сегодня мы начнем разговор о таком инструменте как Transition Matrix . Чтобы ввести вас в контекст я немного расскажу о бизнес-модели для которой я строил Transition Matrix. Это бизнес-модель, в которой клиент: выбирает репетитора, оформляет заявку на обучение (лид), пополняет свой баланс (клиент), планирует уроки на определенные даты и собственно занимается с репетитором в эти даты. Если (1) действие удачное (репетито...